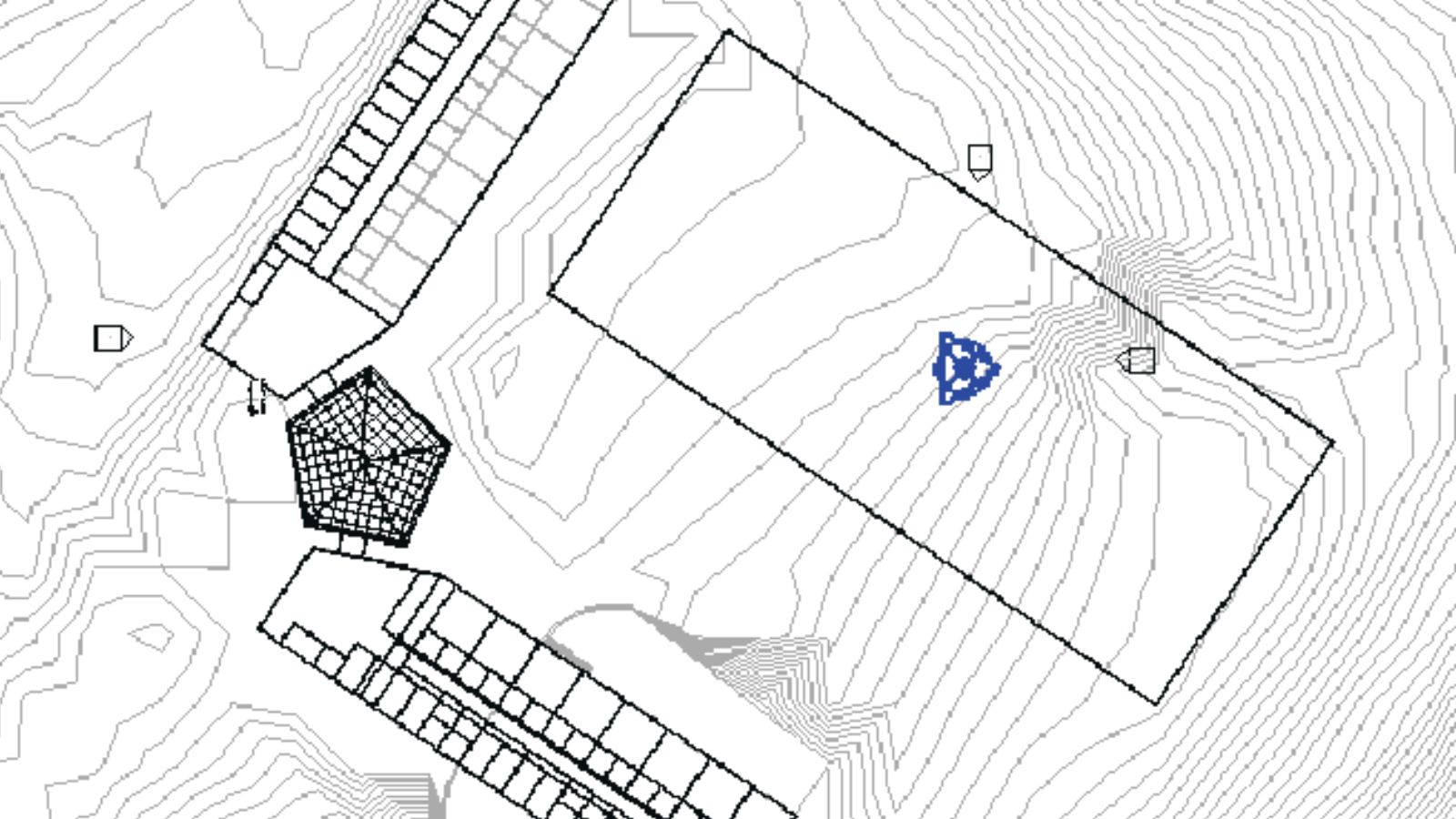
‘Embrace the Ditch,’ and Other Lessons Learned in Duke CEE’s Overture Engineering
Civil and environmental engineering students learn to design buildings within less-than-optimal parameters in a collaborative capstone course
We’re sorry, but that page was not found or has been archived. Please check the spelling of the page address or use the site search.
Still can’t find what you’re looking for? Contact our web team »
Read stories of how we’re teaching students to develop resilience, or check out all our recent news.
Civil and environmental engineering students learn to design buildings within less-than-optimal parameters in a collaborative capstone course

On a Star Wars-themed field of play, student teams deployed small robots they had constructed

Two projects from First-Year Design course are patent-pending. Student surveys suggest the course also fosters teamwork, leadership and communication skills.
Apr 23
Drug discoveries have been instrumental in improving global health over the last century, but the median drug now takes about 10 years to bring to market and costs over a […]
4:00 pm – 4:00 pm
Apr 24
Apr 24
Thomas Lord Department of Mechanical Engineering welcomes Dr. Julian Rimoli, Professor of Mechanical and Aerospace Engineering at University of California — Irvine. Dr. Rimoli will give the lecture, “Discontinuous Compression […]
12:00 pm – 12:00 pm Fitzpatrick Center Schiciano Auditorium Side A, room 1464